В работе был предложен алгоритм сегментации числовых временных рядов, элементы которых имеют многомодальное распределение. Сегментация в данном случае означает отнесение каждого элемента ряда к классу с унимодальным распределением. Такая постановка задачи близка к задаче классификации элементов ряда по заданному признаку. В настоящее время предлагается использовать критерий нормальности для оценки полученных распределений, но в будущих работах планируется предложить модификации, которые могли бы работать и со смесью распределений, отличных от нормального. Было проведено сравнение предлагаемого алгоритма с методами, решающими схожие задачи: метод порога из теории распознавания изображений; алгоритм Дженкса, являющийся одномерным аналогом метода k-средних; и модель гауссовой смеси.
В рамках этапа работы были проведены исследования по эффективности предложенного алгоритма на синтетических и реальных данных. Например, на рисунках 1-3 приведено сравнение действия по разделению на классы синтетически сгенерированных бимодальных рядов (с известной классификацией) с помощью порогового метода и предложенного алгоритма.
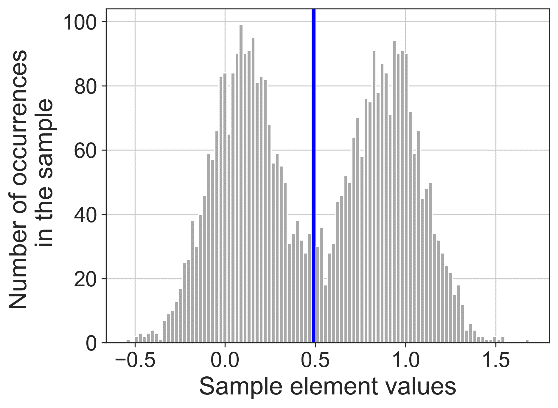
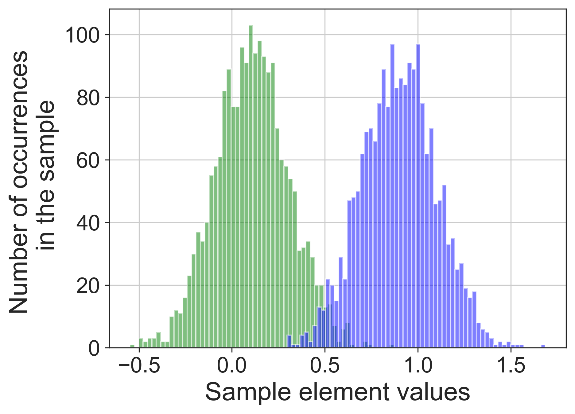
Рис. 1. Результат применения порогового алгоритма сегментации временных рядов (слева) и предложенного алгоритма (справа) к синтетически сгенерированным временным рядам с хорошо разделяемыми модами.
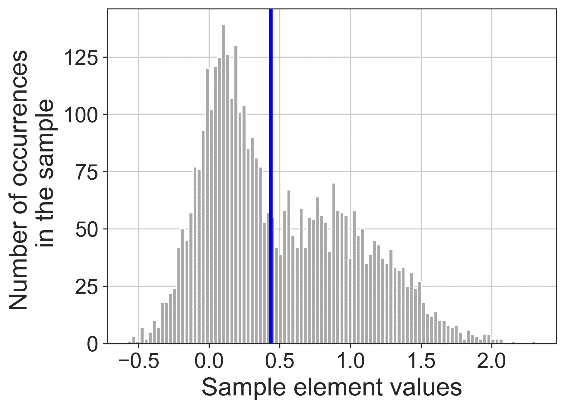
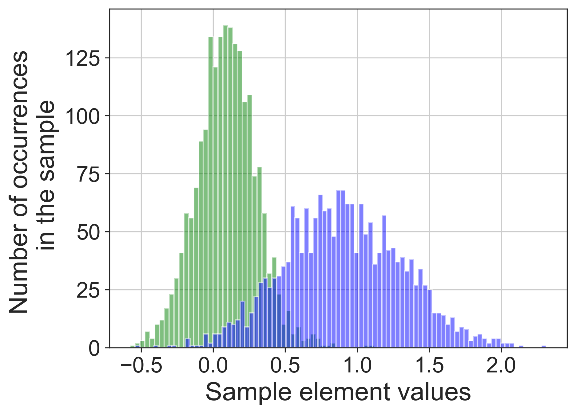
Рис. 2. Результат применения порогового алгоритма сегментации временных рядов (слева) и предложенного алгоритма (справа) к синтетически сгенерированным временным рядам с близко расположенными модами.
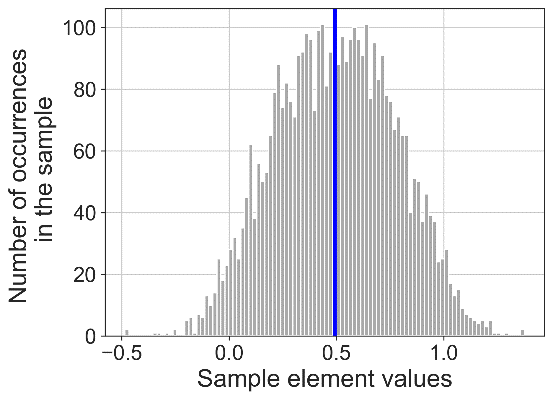
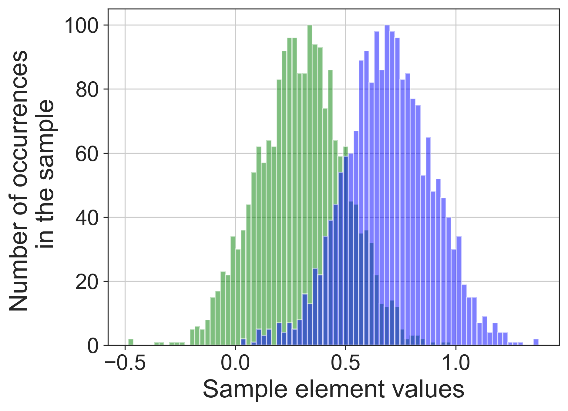
Рис. 3. Результат применения порогового алгоритма сегментации временных рядов (слева) и предложенного алгоритма (справа) к синтетически сгенерированным временным рядам с нечеткой модальностью.
В таблице 1 показаны ошибки классификации для сравниваемых алгоритмов на синтетических данных, представленных на рисунках 1-3. Здесь под ошибкой понимается процент элементов выборки, которые классифицированы неверно.
Таблица 1 — Доля элементов выборки, отнесенных к неправильному классу (процент, %) для синтетических данных, представленных на рисунках 1-3
| Алгоритм | Бимодальная выборка с | ||
| хорошо разделимыми модами (рис. 1) | близко расположенными модами (рис. 2) | нечеткой модальностью (рис. 3) | |
| Пороговый алгоритм | 2.53 | 8.25 | 15.73 |
| Алгоритм Дженкса | 2.50 | 12.58 | 15.78 |
| Модель гауссовой смеси | 2.60 | 9.45 | 15.65 |
| Предложенный алгоритм | 0.00 | 0.60 | 0.23 |
Как видно из таблицы 1, алгоритм даёт на порядки меньшую ошибку сегментации по сравнению с конкурентными методами. Это происходит по следующей причине. Общим для существующих алгоритмов, решающих схожую задачу, является то, что они классифицируют исходные данные по D-классам, не используя возможную связность нескольких соседних элементов (свойство, важное для временных рядов). Это приводит к тому, что классификация для таких методов основана на нахождении D-1 значения между минимумом и максимумом выборки всех элементов исходного ряда. Именно по этим значениям элементы ряда разбиваются на классы. Авторский алгоритм предлагает сравнивать не отдельные элементы временного ряда, а некоторый отрезок, удовлетворяющий вводимому нами в рассмотрение условию однородности сегмента
X_i^j=\{x_i,x_{i+1},...,x_j \},i < j \ \ временного \ \ ряда \ \ X=\{x_1,x_2,...,x_n \} \ \\ \ |maxX_i^j -minX_i^j |≤T,\ \ где\ \ T- гиперпараметр \ \ метода.Узким местом предлагаемого алгоритма является оптимальный выбор порогового значения ![]() , определяющего однородность подпоследовательности. Здесь в качестве критерия предлагается минимум максимумов значения статистики Харке-Бера, полученных для
, определяющего однородность подпоследовательности. Здесь в качестве критерия предлагается минимум максимумов значения статистики Харке-Бера, полученных для ![]() классов при переборе допустимых значений
классов при переборе допустимых значений ![]() . Однако, распределение элементов реального временного ряда редко представляет собой смесь нормальных распределений. В этом случае соответствие между минимумом статистики Харке-Бера и ошибкой сегментации остаётся открытой проблемой. Тем не менее, для реализации предлагаемого алгоритма сегментации временных рядов условие выбора значения
. Однако, распределение элементов реального временного ряда редко представляет собой смесь нормальных распределений. В этом случае соответствие между минимумом статистики Харке-Бера и ошибкой сегментации остаётся открытой проблемой. Тем не менее, для реализации предлагаемого алгоритма сегментации временных рядов условие выбора значения ![]() является переменным и может быть легко заменено на более подходящее для конкретной ситуации. Более подробное описание метода и сравнение его на других наборах данных приведено в статье.
является переменным и может быть легко заменено на более подходящее для конкретной ситуации. Более подробное описание метода и сравнение его на других наборах данных приведено в статье.